+
-
1. Knowledge Base (Wissensbasis)
Legen Sie eine neue Wissensbasis an und vergeben Sie für diese einen Namen. Fertig!
In dieser Wissensbasis werden alle Spektren sowie Ihre Einstellungen und die angelernten "Recognition Modules" gespeichert. Dies geschieht automatisch,
so dass Sie nicht Gefahr laufen, Ihre Daten zu verlieren.

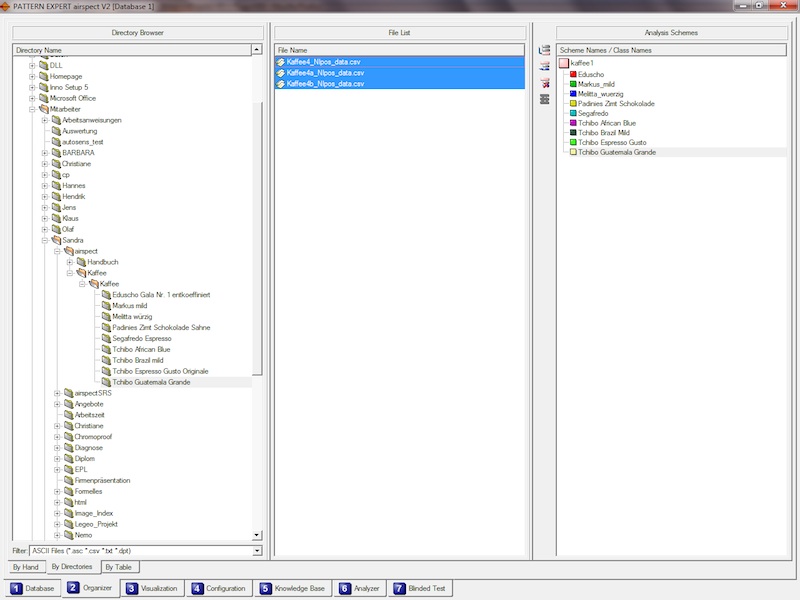
Organisieren Sie Ihre Spektren. Laden Sie Ihre Spektrendateien oder benutzen Sie den Verzeichnisbaum und importieren Sie ganze
Verzeichnisse mit Spektrendateien per Drag & Drop. Haben Sie Ihre Daten bereits in Tabellenform katalogisiert, können Sie diese
Tabelle über die Zwischenablage importieren und sich mit wenigen Klicks alle aufgeführten Dateien bequem suchen lassen.
Erstellen Sie Ihre Klassen, in welche die Spektren zu unterscheiden sind, und ordnen Sie diese Klassen Ihren Spektren zu. Wenn Sie
die Importmöglichkeiten über die Verzeichnisse oder über die Tabelle nutzen, geschieht dies sogar automatisch.
Sie können einige Spektren als "unused" deklarieren, um diese beim Anlernen Ihres Systems auszuschließen. Der Vorteil dieser Option besteht
darin, dass Sie die "unused" Spektren später für die Beurteilung der Vorhersage-Qualität verwenden können.
Die Software PATTERN EXPERT airspect
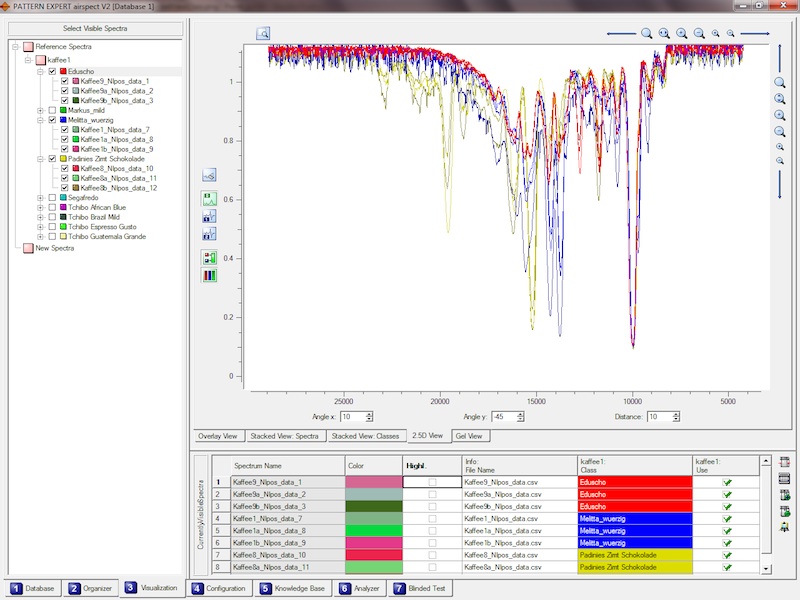
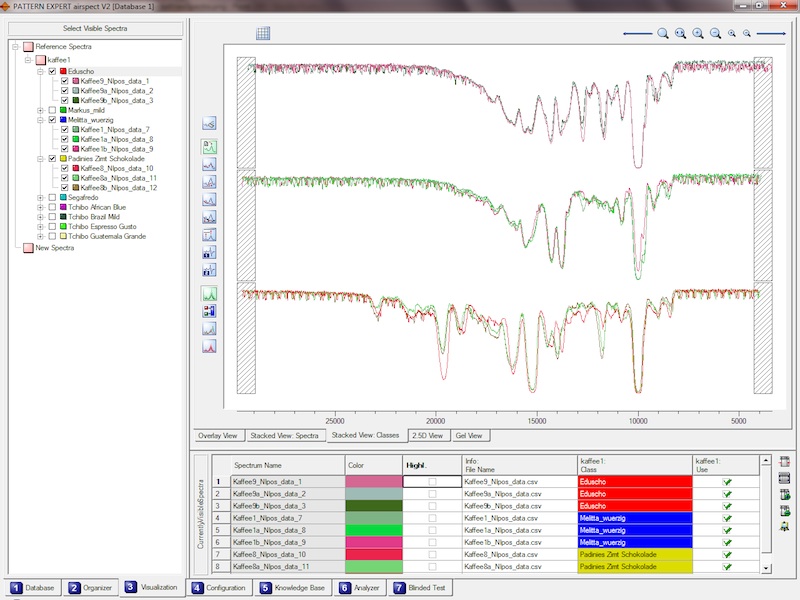
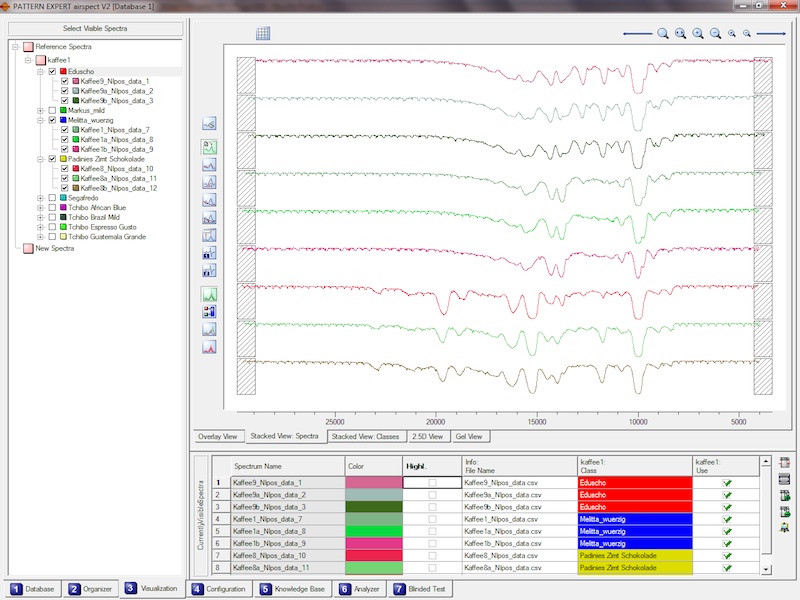
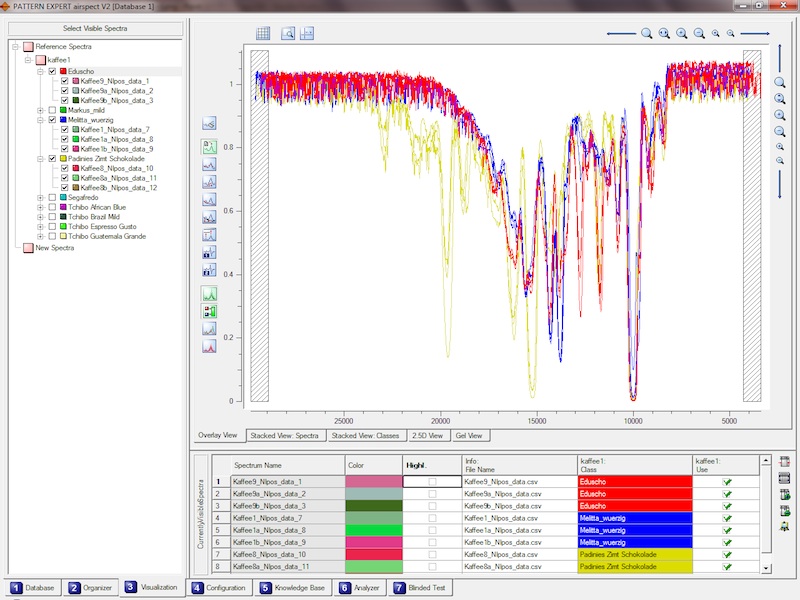
stellt umfangreiche Möglichkeiten zur Visualisierung Ihrer Spektren bereit. Betrachten Sie die Spektren
einzeln oder zusammen, betrachten Sie die Klassenmittelwertsspektren sowie deren Standardabweichung und das Ganze
übereinander, gestaffelt oder perspektivisch, oder nutzen Sie die "Gel-View"-Funktion um von oben auf Ihre Spektren zu schauen.

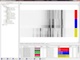
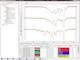
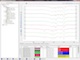
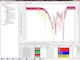
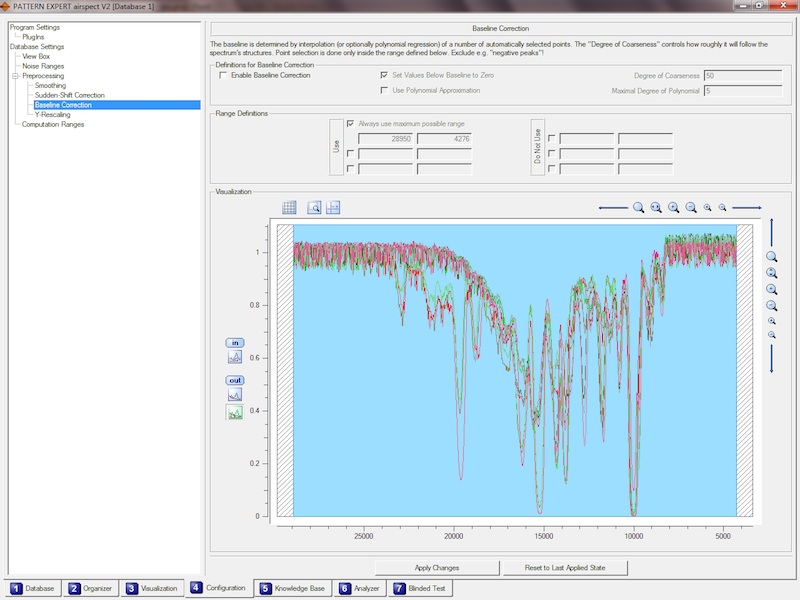
Konfigurieren Sie die Prozesse zur Bearbeitung Ihrer Spektren, die notwendig sind, um Ihre Spektren vergleichbar zu machen.
Dabei können eine Einschränkung des verwendeten Spektralbereiches, eine Glättung, eine Korrektur von Sprüngen (Gitterspektrometer), eine
Baseline-Korrektur, die Normierung des Wertebereichs (Rescaling) und ein Peak Alignment eingestellt werden. Wie sich die Einstellungen
auswirken, sehen Sie in einem Vorschaufenster. Die Einstellungen werden automatisch auf alle Spektren in gleicher Weise angewendet.
Geben Sie zuletzt noch an, welche Bereiche bei der Auswertung Ihrer Spektren verwendet werden sollen, oder
belassen Sie es bei der Voreinstellung, welche den maximalen möglichen Bereich heranzieht - das Lernsystem findet später automatisch die
relevanten Bereiche!
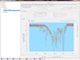
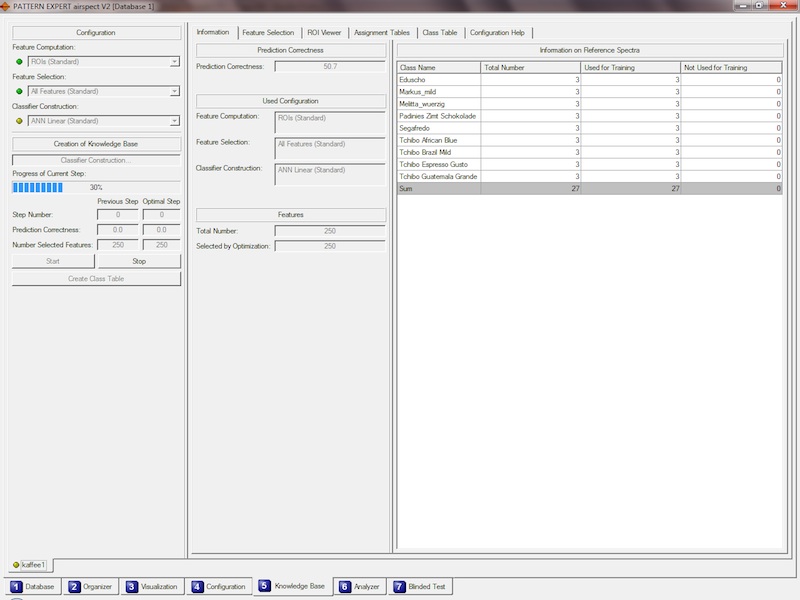
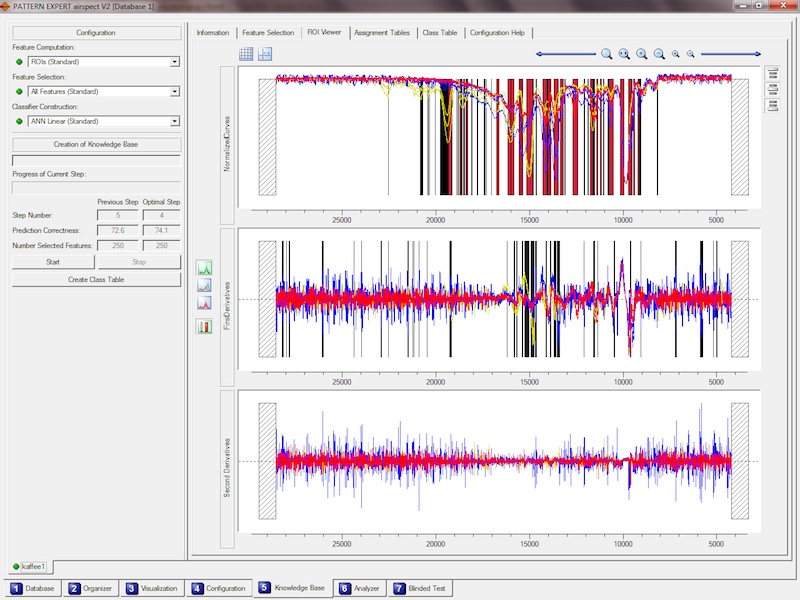
Diese Programmfunktion ist das Herz Ihres Systems. Hier erzeugen Sie die intelligenten Auswerteverfahren - Recognition Modules - mit Hilfe von
lernfähigen Mustererkennungsalgortihmen, die für Ihre jeweilige Anwendung optimal konfiguriert zur Verfügung stehen.
Basierend auf einem von Ihnen frei gewählten Skript werden zunächst vollautomatisch Spektralbereiche ausgewählt, welche für die
Beantwortung Ihrer Klassifikations-Fragestellung relevant sein könnten. Zusätzlich wird für jedes Spektrum ein Wert für den jeweiligen Bereich errechnet.
Dies ist die "Feature Computation". Im nächsten Schritt "Feature Selection", zeigt sich nun, welche dieser Bereiche für die Klassifikation
notwendig sind. Dafür werden zum Beispiel Scoring-Verfahren und auch evolutionäre Algortihmen verwendet.
Mit den so ermittelten, tatsächlich relevanten Bereichen wird im letzten Schritt - der "Classifier Construction" - ein optimaler Klassifikator erstellt,
welcher die Trennung in Ihre Klassen am Besten meistert. Dieser Klassifikator kann nun verwendet werden, um für neue, unbekannte Spektren die
richtige Klasse zu bestimmen.
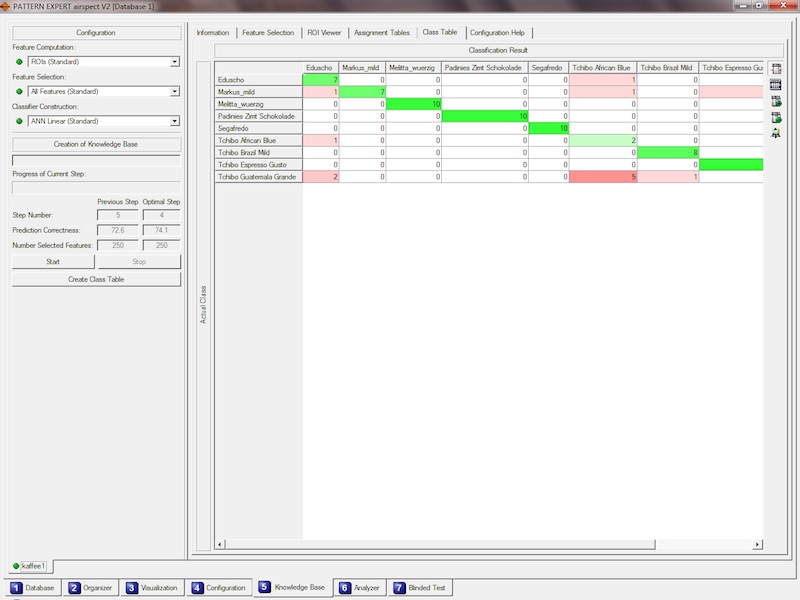
Ihnen stehen umfangreiche Hilfsmittel zur Verfügung, um diese relevanten Bereiche aufzulisten oder grafisch darzustellen,
"verdächtige" Spektren zu ermitteln, zu prüfen und zu erkennen, dass diese vielleicht zu sehr verrauscht sind, dass sie
prinzipiell falsch aufgenommen wurden oder dass sie vielleicht sogar versehentlich der falschen Klasse zugeordnet wurden.
Weiterhin wird Ihnen die Qualität des Recognition Module mittels einer Schätzung der prozentualen Treffergenauigkeit angezeigt.
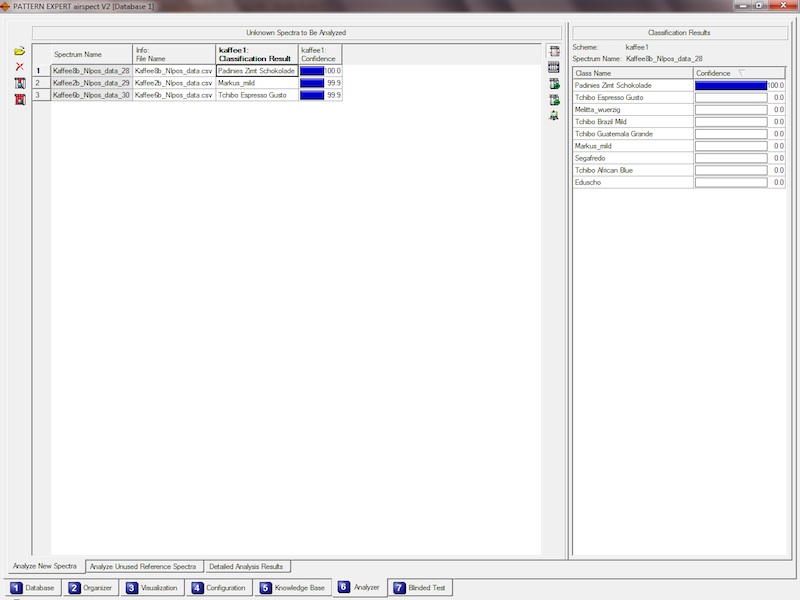
Mit der Funktion Recognition werten Sie neue unbekannte Spektren aus.
Haben Sie am Anfang die Möglichkeit genutzt, einige Ihrer Spektren als "unused" zu definieren, und diese somit vom Trainingsprozeß
ausgenommen, so können Sie diese jetzt klassifizieren, also sich vom System die Klasse vorhersagen lassen - einschließlich eines
prozentualen Konfidenzwertes für die Richtigkeit der Einordnung. Diese Entscheidung wird mit der tatsächlichen Klasse verglichen. So erhalten
Sie ein weiteres Maß für die Vertrauenswürdigkeit des Systems, das auf dem Test einer unabhängigen Testmenge beruht..
Für neue, völlig unbekannte Spektren können Sie mit der Funktion Recognition die Klassenzugehörigkeit ermitteln. Sie erhalten neben dem
Klassifikationsergebnis einen aussagekräftigen Konfidenzwert. Darüber hinaus stehen Hilfsmittel zur Verfügung, um die unbekannten
Spektren mit Spektren aus der Wissensbasis zu vergleichen und möglichst ähnliche Referenzspektren zu finden. Hier wird also in Zukunft,
nachdem Sie Ihre Wissensbasis komplett aufgebaut haben, die praktische Anwendung des erworbenen Wissens stattfinden.
+
-
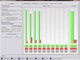
7. External Cross Validation
Dieser 7. und letzte Schritt ist optional und nicht zwingend notwendig für die Arbeit mit Ihrer Wissensbasis.
Mit diesem Schritt wird ein Praxistest durchgeführt. Es werden zyklisch stets ein paar Ihrer Spektren ausgeschlossen und mit dem
Rest ein Recognion Module erzeugt. Anschließend werden die weggelassenen Spektren auf ihre richtige Klassenzuordnung bei der
Klassifikation getestet. So wird das Verhalten bei neuen, unbekannten Spektren getestet und Sie erhalten eine zuverlässige
Aussage, wie sich Ihr System in Zukunft verhalten wird.
Dieser Vorgang läuft vollautomatisch ab und die Ergebnisse werden grafisch dargestellt.

 Bei der intuitiven Bedienung des Programms gehen Sie am besten
Bei der intuitiven Bedienung des Programms gehen Sie am besten