In der Mustererkennung versucht man, in Daten homogene Muster oder Ähnlichkeiten zu erkennen und dieses Wissen auf neue
unbekannte Daten anzuwenden, was man mit generalisieren bezeichnet. Der Ähnlichkeitsbegriff steht dabei an ganz zentraler Stelle.
Im konkreten Anwendungsfall geht es immer darum, welches ähnliche Objekte sind und worin sich ihre Ähnlichkeit auszeichnet.
Numerische Verfahren der Mustererkennung, im Gegensatz zu den regelbasierten Verfahren, die in Pattern Expert nicht enthalten sind,
können mathematisch mit Hilfe des Funktionsbegriffes beschrieben werden, deshalb werden sie auch numerische Verfahren genannt.
Die zu untersuchenden Objekte werden mit Hilfe von Eigenschaften, Merkmale genannt, beschrieben. Jedem Objekt entspricht also ein
n-Tupel von Zahlen, üblicherweise von reellen Zahlen. Jedem dieser n-Tupel wird dann eine Klasse Y zugeordnet. Die Zahl Y kann
aus einer endlichen Menge, dann sprechen wir von einem Klassifikationsproblem, oder aus der Menge der reellen Zahlen ausgewählt
werden, dann sprechen wir von einem Regressionsproblem.
Y=f(x1,...,xn)
Für eine Lernmenge sei die Funktion f vorgegeben. Gesucht ist nun eine Funktion F, die auf der Lernmenge möglichst gut mit der
Funktion f übereinstimmt, und ausserhalb der Lernmenge möglichst sinnvolle Vorhersagen macht. Die Funktion F bezeichnet man
traditionell auch als Klassifikations- oder Regressionsalgorithmus.
Die Qualität der Generalisierung überprüft man dadurch, indem man die Funktion F auf einer Testmenge, für die f bekannt ist, berechnet
und die Funktionswerte vergleicht. Wie man nun die Ergebnisse vergleicht, bzw. die Fehler auszählt, ist im speziellen Fall nicht so
einfach zu entscheiden. Zum Beispiel in der Medizin sind falsch positive Diagnosen, der Patient ist gesund aber ein Diagnosetest liefert
ein positives Ergebnis, anders zu bewerten als ein falsch negatives Ergebnis, wobei der Patient zwar krank ist, der Test jedoch
negativ ausfällt.
Wie man nun einen solchen Klassifikationsalgorithmus F berechnet, das ist Sache der Lernverfahren.
Wir wollen dies an einem einfachen Beispiel demonstrieren. In Wahrheit ist die Sache meist viel komplizierter, deshalb macht es ja Sinn,
dass sich zum Beispiel Firmen auf solche Methoden spezialisieren.
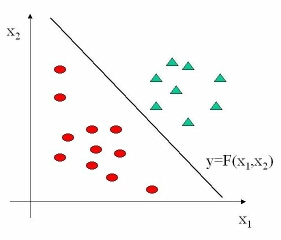
Der einfachste Fall ist in der Abbildung dargestellt. Die Objekte sind in der Ebene der reellen Zahlenebene angeordnet. Gesucht ist nun
eine möglichst einfache Funktion, die die zwei Klassen, als Kreise und Dreiecke kenntlich gemacht, möglichst gut trennt. Die Gerade
Y=F(x1,x2) erfüllt offenbar diesen Zweck schon recht gut. Lernverfahren, wie man also solch eine Gerade findet, sind ein sehr gutes
Beispiel, um die allgemeinen Prinzipien des maschinellen Lernens zu erklären. Von dieser einfachen Idee ausgehend kann man
zum Beispiel sehr schön die bekannten Support Vector Machines - SVM - erklären.
Lernverfahren für künstliche neuronale Netze und Bayes'sche Klassifikatoren sind in der Literatur ausreichend beschrieben worden,
so dass es an dieser Stelle nur eine Wiederholung bekannter Tatsachen wäre. Jedoch ist es oft ein sehr weiter Weg bis man zu
ausgereiften implementierten Methoden kommt.
Für die Praxis ist neben den geeigneten Lernverfahren oft die Auswahl und Entwicklung geeigneter Merkmale der ausschlaggebende
Erfolgsfaktor. Bewertungsverfahren, auch Merkmals-Scores genannt, sind bei der Auswahl und Entwicklung geeigneter Merkmale oft
sehr hilfreich. In Pattern Expert sind eine Reihe solcher Methoden implementiert. Die Merkmals-Scores sind für unterschiedliche
Anwendungsgebiete unterschiedlich geeignet. So sind für SNP-Analysen völlig andere Merkmals-Scores notwendig, als zum Beispiel für die
Analyse von Aktivitätsmustern von lebenden Nervenzellen. Als Beispiele für Scores seien der Fisher-Score und die "mutual
information divergence" - MID - genannt.

