In pattern recognition one tries to find homogeneous patterns and similarities in complex data, and then exploit the "knowledge" found in
this way for analyzing new unknown data. The latter is called "generalization". Here, the crucial point is the notion of similarity. For any
concrete application, the question is: which objects are considered similar and what is it exactly that makes them similar.
In contrast to rule-based methods for pattern recognition (which are not used by Pattern Expert), the numerical methods (which we
use) may be described mathematically by using the notion of a function. The basic idea of the numerical methods is to describe the
objects, which are to be analyzed, in terms of characteristic features i.e. one needs to define a mapping, by which each object
corresponds to some n-tuple of real numbers. The n individual components of the tuple are called the "features" of the object. Then,
classification is done by assigning a class Y to each possible value of the n-tuple. Here, Y may be restricted to some finite set - this is
called a "classification problem" - or it may be a continuous variable - in this case we have a "regression problem".
Y = F(x1,...,xn)
Let F(x1,...,xn) be the function which assigns the correct class Y to the feature values x1,...,xn of the (known) objects contained in
some learning set. Now, the aim is to find another function F (defined for all possible feature values), which approximates F as close
as possible on the training data, and which, at the same time, allows for a meaningful prediction outside the training set. Traditionally,
the function F is called classification or regression algorithm. The learning algorithm, on the other hand, is the method which is used to
find F by exploiting the information contained in F.
The generalizing power of the resulting classifier is evaluated by applying the function F to a set of test data, which have not been
used for training and for which the correct class assignments are known, so that the results of F can be compared to known target
values. Here, the final assessment of test data results depends on the current application. In a medical application, e.g. a false positive
classifier decision (i.e. a healthy person is claimed to be diseased) will receive a different assessment than a false negative result (i.e.
an actual disease is not detected).
The purpose of the employed learning methods is to calculate the classification algorithm F.
Let us demonstrate this using a simple example. In real applications the situation usually is much more complicated (this is why it is
wise to use tools developed by companies which have specialized in this type of problems).
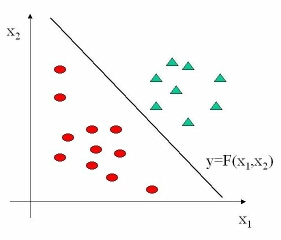
The above diagram shows the simplest possible case. The objects are mapped to points in two-dimensional space and belong to one
out of two different classes (indicated by ellipses or triangles resp). Now, the aim is to find a function F, which separates the two
classes as clearly as possible and which, at the same time, is "as simple as possible". In our case, the straight line Y = F(x1,x2) is a
good solution. Those learning algorithms, which seek to find a straight line like this, may be used as good exemplifications for
understanding the general principles of machine learning e.g. this simple idea may be the basis for explaining the well known "Support
Vector Machines" (SVM).
We do not try to describe in detail the various learning algorithms here, because there are many good books dealing with that subject.
In a given application, however, it very often turns out to be a long task to develop and implement the appropriate methods.
For practical applications, another crucial point - in addition to carefully selecting classification and learning algorithms - is to find the
appropriate mapping of objects to feature values. Feature calculation and selection algorithms have to be developed, implemented and
tested. To achieve this feature assessment methods (also called feature "scores") are often very helpful. The technology framework
that Pattern Expert provides, uses a variety of these methods. It turns out to be necessary to use different types of feature scores in
different applications. e.g. in SNP analysis one
needs to use completely different feature scores than in the
analysis of activity patterns of living neurons . Two examples of feature scores are the "Fisher Score" and the "Mutual Information
Divergence" (MID).

